The Future Development of AI+Web3 (Part 2): Infrastructure
Written by: Future3 Campus
This article is the second part of Future3 Campus AI+Web3 industry research report, which details the development potential, narrative logic and representative head projects of the infrastructure layer.The future development path of AI+Web3 (I): Industry landscape and narrative logic.
Infrastructure is the definite growth direction of AI development
Explosive growth in AI computing power demand
In recent years, the demand for computing power has grown rapidly, especially after the launch of the LLM large model, the demand for AI computing power has detonated the high-performance computing power market. OpenAI data shows that since 2012,The amount of computing used to train the largest AI models is growing exponentially, doubling every 3-4 months on average, far outpacing Moore’s LawThe growing demand for AI applications has led to a rapid increase in demand for computing hardware. It is estimated that by 2025, the demand for computing hardware for AI applications will increase by approximately 10% to 15%.
Affected by the demand for AI computing power, the data center revenue of GPU hardware manufacturer NVIDIA continues to grow. In Q2 of 2023, the data center revenue reached $10.32B, an increase of 141% from Q1 of 2023 and 171% from the same period last year. In the fourth quarter of fiscal year 2024, the data center business accounted for more than 83% of revenue, an increase of 409%, of which 40% was used for reasoning scenarios of large models, showing a strong demand for high-performance computing power.
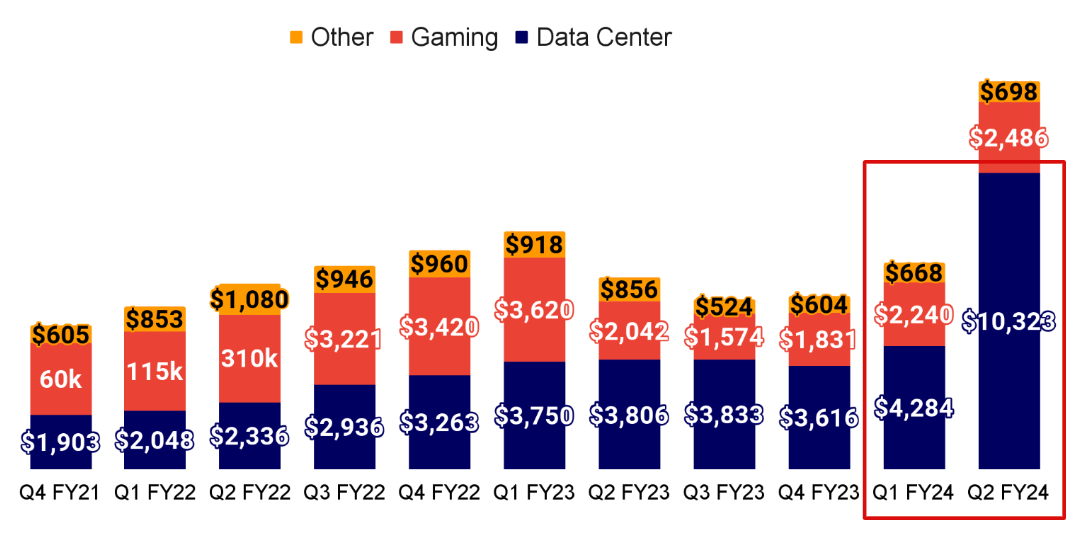
At the same time, the need for massive data also puts forward requirements for storage and hardware memory, especially in the model training stage, which requires a large number of parameter inputs and a large amount of data storage. The storage chips used in AI servers mainly include: high bandwidth memory (HBM), DRAM and SSD.AI server workloads require greater capacity, higher performance, lower latency, and higher response speed.According to Micron's calculations, the amount of DRAM in AI servers is eight times that of traditional servers, and the amount of NAND is three times that of traditional servers.
Supply and demand imbalance drives high computing power costs
Generally speaking, computing power is mainly used in the training, fine-tuning, and inference stages of AI models. Especially in the training and fine-tuning stage, due to the larger data parameter input and computing volume, and the higher requirements for the connectivity of parallel computing, higher-performance and more interconnected GPU hardware is required, usually a high-performance GPU computing power cluster.With the development of large models, the computational complexity has also increased sharply, requiring more high-end hardware to meet the needs of model training..
Taking GPT3 as an example, based on the situation of 13 million independent users accessing, the corresponding chip demand is more than 30,000 A100 GPUs. Then the initial investment cost will reach a staggering $800 million, and the daily model inference cost is estimated to be $700,000.
At the same time, according to industry reports, in the fourth quarter of 2023, NVIDIA GPU supply was strictly restricted worldwide, resulting in a significant shortage of supply in the global market. NVIDIA's production capacity is limited by TSMC, HBM, CoWos packaging and other production capacities, and the "serious shortage problem" of H100 will continue at least until the end of 2024.
Therefore, the rising demand for high-end GPUs and the limited supply have driven up the current high prices of GPUs and other hardware., especially companies like NVIDIA that occupy the core of the bottom layer of the industry chain, can further obtain value dividends through leading monopoly. For example, the material cost of NVIDIA's H100 AI accelerator card is about US$3,000, and the selling price has reached about US$35,000 in mid-2023, and even sold for more than US$40,000 on eBay.
AI infrastructure occupies the core value growth of the industry chain
According to a report by Grand View Research, the size of the global cloud AI market is estimated to be US$62.63 billion in 2023 and is expected to grow to US$647.6 billion by 2030, with a compound annual growth rate of 39.61%. This data reflects the growth potential of cloud AI services and their important share in the entire AI industry chain.
According to a16z’s estimates,A large amount of funds in the AIGC market eventually flowed to infrastructure companiesOn average, application companies spend about 20-40% of revenue on inference and fine-tuning for each customer. This is typically paid directly to the cloud provider of the compute instances or to third-party model providers - who in turn spend about half of their revenue on cloud infrastructure. Therefore, it is reasonable to guess that 10-20% of total AIGC revenue today goes to cloud providers.
At the same time, a larger part of the computing power demand lies in the training of large AI models, such as various large LLM models. Especially for model start-ups, 80-90% of the cost is used for the use of AI computing power.Overall, AI computing infrastructure (including cloud computing and hardware) is expected to account for more than 50% of market value in the initial stage..
Decentralized AI computing
As mentioned above, the current high cost of centralized AI computing is mainly due to the growing demand for high-performance infrastructure for AI training. However, in reality, there is still a large amount of idle computing power in the market, resulting in a mismatch between supply and demand. The main reasons are:
-
Due to memory limitations, the model complexity does not increase linearly with the number of GPUs required.:Current GPUs have computing power advantages, but model training requires a large number of parameters to be stored in memory. For example, for GPT-3, in order to train a model with 175 billion parameters, more than 1 TB of data needs to be stored in memory - this exceeds any GPU currently available, so more GPUs are needed for parallel computing and storage, which in turn leads to idle GPU computing power. For example, from GPT3 to GPT4, the scale of model parameters increased by about 10 times, but the number of GPUs required increased by 24 times (without considering the increase in model training time). According to relevant analysis, OpenAI used approximately 2.15e25 FLOPS in the training of GPT-4, and trained for 90 to 100 days on approximately 25,000 A100 GPUs, with a computing power utilization rate of approximately 32% to 36%.
In the face of the above problems, designing high-performance chips or dedicated ASIC chips that are more suitable for AI work is the direction that many developers and large companies are currently exploring.Another perspective is to comprehensively utilize existing computing resources, build a distributed computing network, and reduce the cost of computing power through leasing, sharing, and scheduling computing power.In addition, there are many idle consumer-grade GPUs and CPUs in the market. Their computing power is not strong, but in some scenarios or when configured with existing high-performance chips, they can meet existing computing needs. The most important thing is that they are in sufficient supply, and distributed network scheduling can further reduce costs.
Therefore, distributed computing power has become a direction for the development of AI infrastructure. At the same time, because Web3 and distribution have similar concepts, decentralized computing power networks are also the main application direction of the current Web3+AI infrastructure. Currently, the Web3 decentralized computing power platforms on the market can generally provide prices that are 80%-90% lower than centralized cloud computing power.
Although storage is also the most important infrastructure for AI, the requirements for large scale, ease of use, and low latency make centralized storage more advantageous. Distributed computing networks have a more practical market due to their significant cost advantages.Xiaobai NavigationBe able to enjoy greater benefits brought by the explosion of the AI market.
-
Model reasoning and small model training are the core scenarios of current distributed computing powerDistributed computing power inevitably increases communication problems between GPUs due to the dispersion of computing power resources, thus reducing computing power performance. Therefore, distributed computing power is more suitable for scenarios with less communication requirements and can support parallelism, such as the reasoning stage of large AI models and small models with relatively few parameters, which are less affected by performance.In fact, with the development of AI applications in the future, reasoning is the core requirement of the application layer. Most companies do not have the ability to train large models, so distributed computing power still has long-term potential in the market..
-
-
High-performance distributed training frameworks designed for large-scale parallel computing are also emerging.For example, innovative open source distributed computing frameworks such as Pytorch, Ray, and DeepSpeed provide stronger basic support for developers to use distributed computing power for model training, making distributed computing power more applicable in the future AI market.
Narrative logic of AI+Web3 infrastructure projects
We see that distributed AI infrastructure has strong demand and long-term growth potential, so it is an area that is easy to describe and favored by capital. At present, the main projects of the infrastructure layer of the AI+Web3 industry are basicallyWith decentralized computing networks as the main narrative, low cost as the main advantage,TokenIncentives are the main method to expand the network, and serving AI+Web3 customers is the main goal. It mainly includes two levels:
1.A relatively pure decentralized cloud computing resource sharing and leasing platform: There are many early AI projects, such as Render Network, Akash Network, etc.
-
Computing resources are the main competitive advantage:The core competitive advantages and resources are usually the ability to access a large number of computing power providers, quickly build their basic network, and provide easy-to-use products to customers. Many companies and miners engaged in cloud computing in the early market will find it easier to enter this track.
-
The product threshold is low and the launch speed is fast:For mature products such as Render Network and Akash Network, we can already see tangible growth data and have a certain leading advantage.
-
New entrants’ product homogeneity: Due to the current hot track and the low threshold of such products, a large number of projects that engage in narratives such as shared computing power and computing power leasing have recently entered the market. However, the products are relatively homogeneous, and more differentiated competitive advantages need to be seen.
-
Prefer to serve customers with simple computing needs:For example, Render Network mainly serves rendering needs, and Akash Nerwork provides more CPU resources. Simple computing resource leasing mostly meets the needs of simple AI tasks, but cannot meet the full life cycle needs of complex AI training, fine-tuning, speculation, etc.
2.Providing decentralized computing + ML workflow services:There are many emerging projects that have recently received high financing, such as Gensyn, io.net, Ritual, etc.;
-
Decentralized computing raises the valuation foundation.Since computing power is a deterministic narrative for the development of AI, projects with a computing power foundation usually have a more stable and high-potential business model, resulting in a higher valuation than pure middle-tier projects.
-
Middle-tier services create differentiated advantages.The services in the middle layer are the competitive parts of these computing infrastructures, such as oracles and validators that serve the synchronization of on-chain and off-chain computing of AI, and deployment and management tools that serve the overall workflow of AI. AI workflows are collaborative, have continuous feedback, and are highly complex. Computing power needs to be applied to multiple links in the process. Therefore, a middle layer infrastructure that is easier to use, highly collaborative, and can meet the complex needs of AI developers is competitive at the moment, especially in the Web3 field, where the needs of Web3 developers for AI need to be met. Such services are more likely to take on potential AI application markets, rather than just supporting simple computing needs.
-
Usually a project team with professional operation and maintenance experience in the ML field is required.Teams that can provide the above-mentioned middle-layer services usually need to have a detailed understanding of the entire ML workflow in order to better meet the full life cycle needs of developers. Although such services usually use many existing open source frameworks and tools and may not necessarily have strong technological innovations, they still require teams with rich experience and strong engineering capabilities, which is also a competitive advantage of the project.
By providing services with more favorable prices than centralized cloud computing services but similar supporting facilities and user experience, these projects have gained recognition from many leading capitals. However, the technical complexity is also higher. Currently, they are basically in the narrative and development stages, and there is no complete product yet.
Representative Projects
Render Network
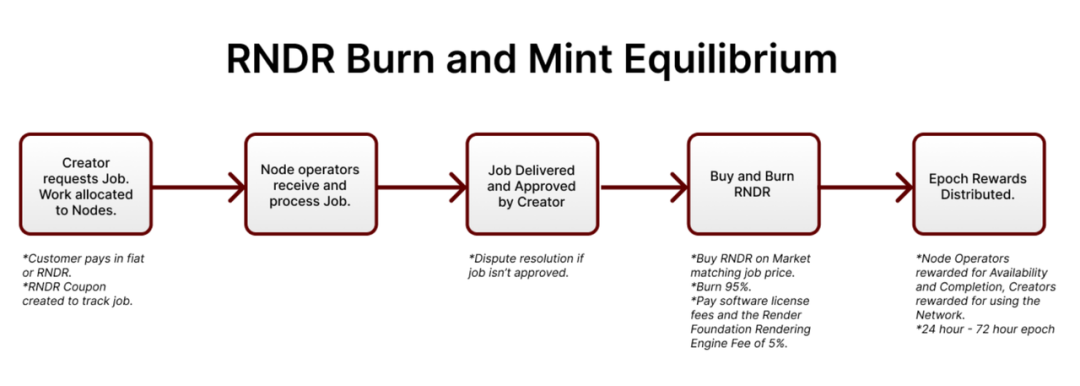
Render Network is aBlockchainThe global rendering platform provides distributed GPUs to provide creators with lower-cost, higher-speed 3D rendering services. After the creator confirms the rendering results,Blockchain网络向节点发送代币奖励。平台提供分布式 GPU 的调度和分配网络,按照节点的用量情况、声誉等进行作业的分配,最大化地提高计算的效率,减少资源闲置,降低成本。
Render Network's token RNDR is a payment token in the platform. Creators can use RNDR to pay for rendering services, and service providers can receive RNDR rewards by providing computing power to complete rendering tasks. The price of rendering services will be dynamically adjusted based on the current usage of the network.
Rendering is a relatively suitable and mature scenario for the use of distributed computing architectureBecause the rendering task can be divided into multiple subtasks and executed in highly parallel manner without the need for excessive communication and interaction between them, the disadvantages of the distributed computing architecture can be avoided to the greatest extent possible, while making full use of the extensive GPU node network to effectively reduce costs.
Therefore, the user demand for Render Network is also considerable. Since its establishment in 2017, Render Network users have rendered more than 16 million frames and nearly 500,000 scenes on the network, and the number of rendering frame jobs and active nodes are both on the rise. In addition, Render Network also launched a natively integrated Stability AI toolset in Q1 2023. Users can use this feature to introduce Stable Diffusion jobs, and the business is no longer limited to rendering jobs but is expanding to the AI field.
Gensyn.ai
Gensyn is a global supercomputing cluster network for deep learning computing, based on Polkadot's L1 protocol. In 2023, it received a $43 million Series A financing led by a16z.
Gensyn's narrative architecture includes not only the distributed computing power cluster of the infrastructure, but also the upper-level verification system, which proves that the large-scale calculations performed outside the chain are performed in accordance with the requirements of the chain.BlockchainTo verify, thus building a trustless machine learning network.
In terms of distributed computing power, Gensyn can support everything from data centers with excess capacity to personal laptops with potential GPUs. It connects these devices into a single virtual cluster that developers can access on demand and use peer-to-peer. Gensyn will create a market where prices are determined by market dynamics and open to all participants, allowing the unit cost of ML computing to reach a fair balance.
而验证体系是 Gensyn 更重要的概念,它希望网络能够验证机器学习任务是否按照请求正确完成,它创新了一种更加高效的验证方法,包含了概率性学习证明、基于图的精准定位协议和 Truebit 式激励游戏三大核心技术点,相比传统区块链中的重复验证方法更加高效。其网络中的参与者包括提交者、求解者、验证者和举报者,来完成整个验证流程。
According to the comprehensive test data of the Gensyn protocol in the white paper, its significant advantages are:
-
Can reduce the cost of AI model training: The estimated hourly cost of NVIDIA V100 equivalent compute on the Gensyn protocol is approximately $0.40, which is 80% cheaper than AWS on-demand compute.
-
A more efficient trustless verification network: According to the tests in the white paper, the time cost of model training of the Gensyn protocol is 1,350% higher than that of Truebit replication, and 2,522,477% higher than that of Ethereum.
However, compared with local training, distributed computing inevitably increases training time due to communication and network problems.The Gensyn protocol adds about 46% of time overhead to model training..
Akash network
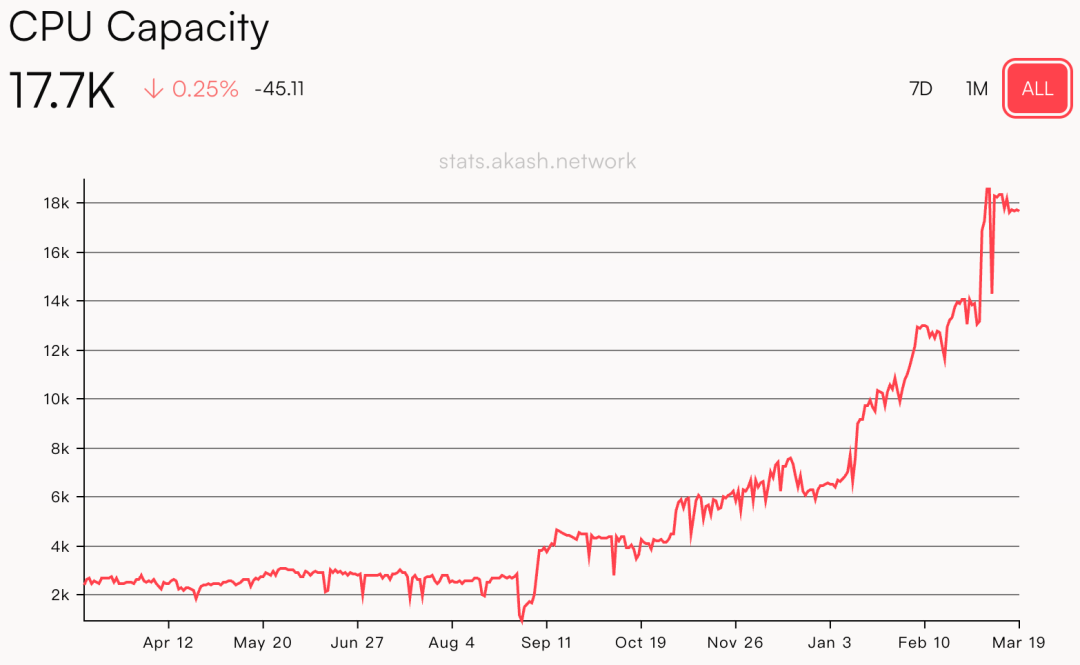
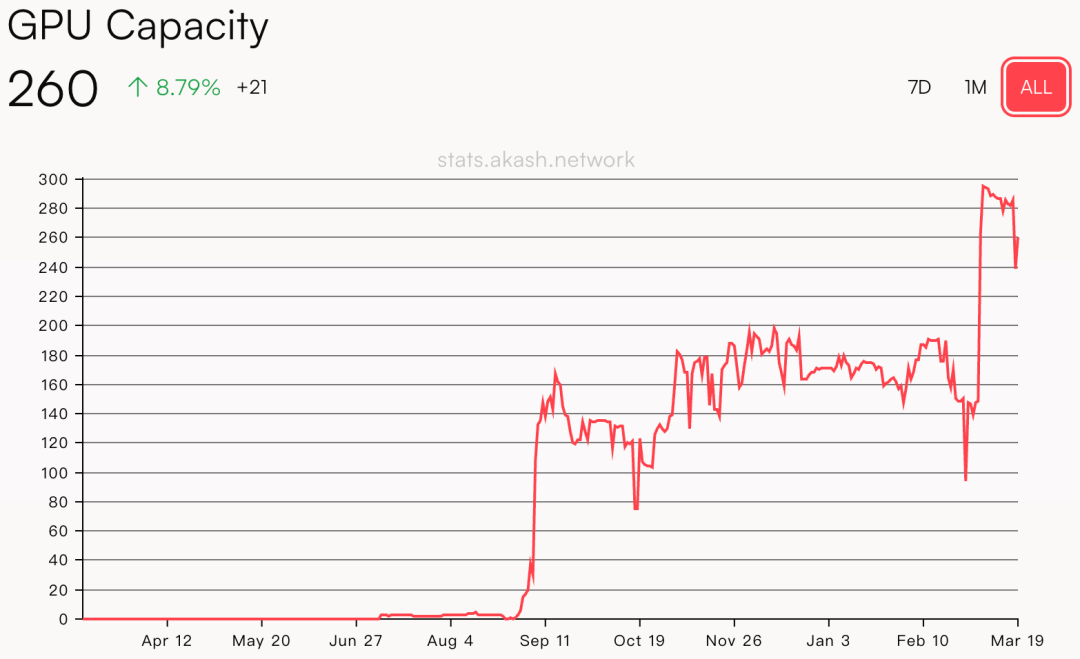
Akash network is a distributed cloud computing platform that combines different technical components to allow users to efficiently and flexibly deploy and manage applications in a decentralized cloud environment. Simply put, it provides users with the ability to lease distributed computing resources.
Akash's underlying infrastructure is provided by multiple infrastructure service providers around the world, which provide CPU, GPU, memory, and storage resources, and provide resources to users for leasing through the upper-layer Kubernetes cluster. Users can deploy applications as Docker containers to use lower-cost infrastructure services. At the same time, Akash uses a "reverse auction" approach to further reduce resource prices. According to estimates on the Akash official website, the service cost of its platform is about 80% lower than that of centralized servers.

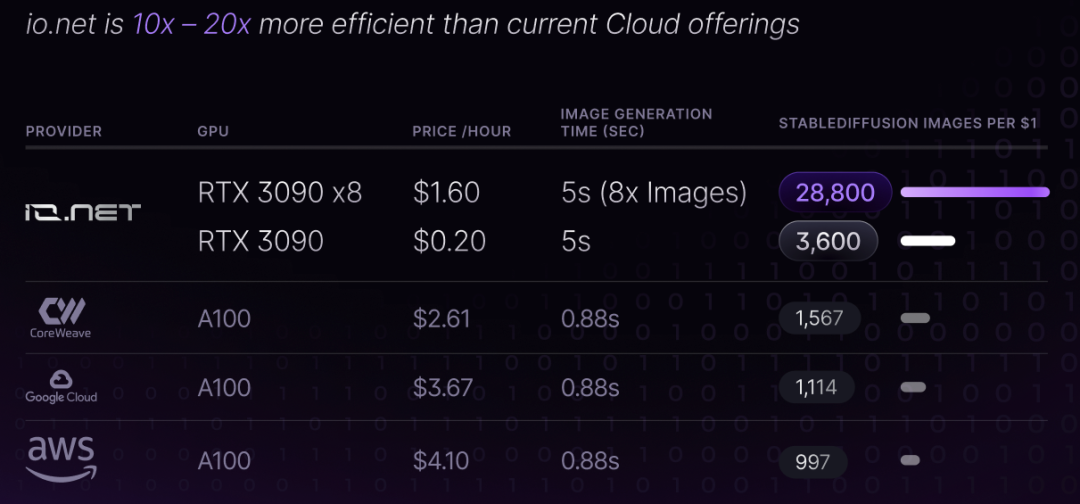
io.net
io.net is a decentralized computing network that connects globally distributed GPUs to provide computing power support for AI model training and reasoning. io.net has just completed a $30 million Series A financing round, with a valuation of $1 billion.
Compared with Render, Akash, etc., io.net is a more robust and scalable decentralized computing network, which is connected to developer tools at multiple levels. Its features include:
-
Aggregate more computing resources: GPUs for independent data centers, crypto miners, and crypto projects such as Filecoin and Render.
-
Core support for AI requirements: Core service capabilities include batch inference and model serving, parallel training, parallel hyperparameter tuning, and reinforcement learning.
-
A more robust technology stack to support more efficient cloud environment workflows: Includes a variety of orchestration tools, ML frameworks (allocation of computing resources, execution of algorithms, and operations such as model training and inference), data storage solutions, GPU monitoring and management tools, etc.
-
Parallel computing capabilities: Integrate Ray, an open source distributed computing framework, embrace Ray's native parallelism, and easily parallelize Python functions to achieve dynamic task execution. Its memory storage ensures fast data sharing between tasks and eliminates serialization delays. In addition, io.net is not limited to Python, but also integrates other leading ML frameworks such as PyTorch and TensorFlow, making it more scalable.
In terms of price, the io.net official website estimates that its price will be about 90% lower than centralized cloud computing services.
In addition, io.net's token IO coin will be mainly used for payment and rewards for services within the ecosystem in the future, or the demander can use a model similar to Helium to burn IO coins and exchange them for the stable currency "IOSD points" for payment.
The article comes from the Internet:The Future Development of AI+Web3 (Part 2): Infrastructure
OpenSea CEO said he had received acquisition intentions, but did not specify when and by whom. Written by: Liam Kelly, DL News Compiled by: Felix, PANews Affected by the collapse of the NFT market last year, OpenSea, which was once valued at $13.3 billion, seems a bit inflated. Now, NFT…